Methodology
1. Methodology
1.1 Research Design and PRISMA Protocol
This systematic literature review adheres to the PRISMA 2020 guidelines for transparent reporting (Matthew J. Page et al. (2021)). We selected PRISMA because: (1) it ensures reproducibility through explicit documentation of search strategies and screening decisions; (2) it minimizes bias by requiring pre-specified inclusion/exclusion criteria; and (3) it facilitates quality assessment through structured checklists. The protocol was not pre-registered but follows established practices for systematic reviews in finance (David Tranfield et al. (2003)).
Our methodological approach combines database searching with citation snowballing to maximize coverage while maintaining quality thresholds. All search queries, screening decisions, and classification rules are documented in a publicly available reproducibility framework, enabling independent verification of all numerical claims in this manuscript.
1.2 Search Strategy
Database Selection
We conducted a comprehensive search of the OpenAlex database (https://openalex.org), a large-scale open bibliometric platform indexing over 250 million scholarly works. OpenAlex was selected over proprietary alternatives (Web of Science, Scopus) for several reasons: (1) comprehensive coverage of finance journals comparable to proprietary databases; (2) open access enabling reproducibility; (3) rich metadata including citation counts, topics, and full-text abstracts; and (4) programmatic API access enabling systematic search automation.
Time Period
The search covered publications from 1990 to 2025. This starting date was selected because return-based style analysis methodologies were introduced by William F. Sharpe (1992), establishing the foundational framework for quantifying investment style and detecting style drift. Earlier work on fund performance evaluation existed but did not employ the style consistency concepts central to this review.
Dual-Corpus Search Methodology
We employed a dual-corpus search strategy to maximize both recall and precision:
Corpus A—Targeted Keyword Search (58 papers): This corpus employed explicit relevance filters requiring style-related terms in title or abstract. Search queries were organized into five tiers:- Core terms: “mutual fund style drift,” “style consistency,” “investment style deviation”
- Related concepts: “closet indexing,” “active share,” “benchmark mismatch,” “window dressing”
- Measurement: “return-based style analysis,” “holdings-based style analysis,” “style box”
- Causes: “fund manager incentives,” “tournament mutual fund,” “flow-performance”
- Classification: “fund classification,” “fund misrepresentation”
A total of 19 search queries were executed, yielding 5,400+ initial records before quality filtering.
Corpus B—Journal Prestige Search (53 papers): This corpus targeted publications in top-tier finance journals with broader search terms (“mutual fund” AND “investment style” OR “fund management”). Target journals included: Journal of Finance, Journal of Financial Economics, Review of Financial Studies, Financial Analysts Journal, Journal of Financial and Quantitative Analysis, Journal of Portfolio Management, and Management Science.After merging and deduplication, we applied keyword-based relevance classification to yield the final corpus of 71 papers (including 8 papers identified through citation snowballing).
1.3 Inclusion and Exclusion Criteria
Table documents the criteria applied at each screening stage.
Table: Inclusion and Exclusion Criteria
| Language | English | Non-English | |
|---|---|---|---|
| Time period | 1990 | ndash;2025 | Before 1990 |
| Asset class | Equity mutual funds | Pension, hedge, ETFs | |
| Topic relevance | Style drift, Active Share | General asset pricing | |
| Quality threshold | Top 25\ |
1.4 Keyword-Based Relevance Classification
To ensure consistent application of inclusion criteria across both corpora, we developed a keyword-based relevance classifier with three categories:
Core keywords (automatic inclusion): Papers containing “style drift,” “style consistency,” or “style timing” in title or abstract were classified as relevant without further screening. Measurement keywords (automatic inclusion): Papers containing “active share,” “closet index,” “style analysis,” “style box,” or “return-based style” were classified as relevant. Contextual keywords (conditional inclusion): Papers containing “investment style” were included only if they also contained “fund” within the same abstract, ensuring focus on managed portfolios rather than individual investor behavior.This classification scheme yielded 91.7\
1.5 Snowball Validation
To validate corpus completeness, we conducted both forward and backward citation snowballing following Claes Wohlin (2014) guidelines:
Forward snowballing: We identified all papers citing our initial 65 corpus papers using OpenAlex citation links. This yielded 1,791 citing papers, of which 22 were already in our corpus. After applying relevance keywords, 65 new potentially relevant papers were identified. Backward snowballing: We examined references cited by 15 high-citation papers in our corpus. This yielded 414 referenced papers, of which 8 were already in our corpus. After keyword filtering, 1 additional relevant paper was identified. Snowball findings: Of the 66 candidate papers identified through snowballing, we systematically reviewed each and added 8 high-quality papers to the corpus. The remaining 58 papers fell into three categories: (1) out of scope (private equity, venture capital, pension funds, bond funds: 28 papers); (2) below quality threshold (working papers with fewer than 10 citations: 15 papers); (3) duplicates (SSRN versions of already-included published papers: 8 papers); and (4) borderline (7 recent papers pending citation accumulation for future updates). The added papers include important contributions on Active Share controversy (Andrea Frazzini et al. (2016)), small-cap drift (Charles Cao et al. (2017)), style consistency (Keith C. Brown & W. V. Harlow (2009)), and ESG window dressing (Fernando Mu{\~n (2022)).1.6 Study Selection Process
Figure presents the PRISMA 2020 flow diagram documenting our study selection process.
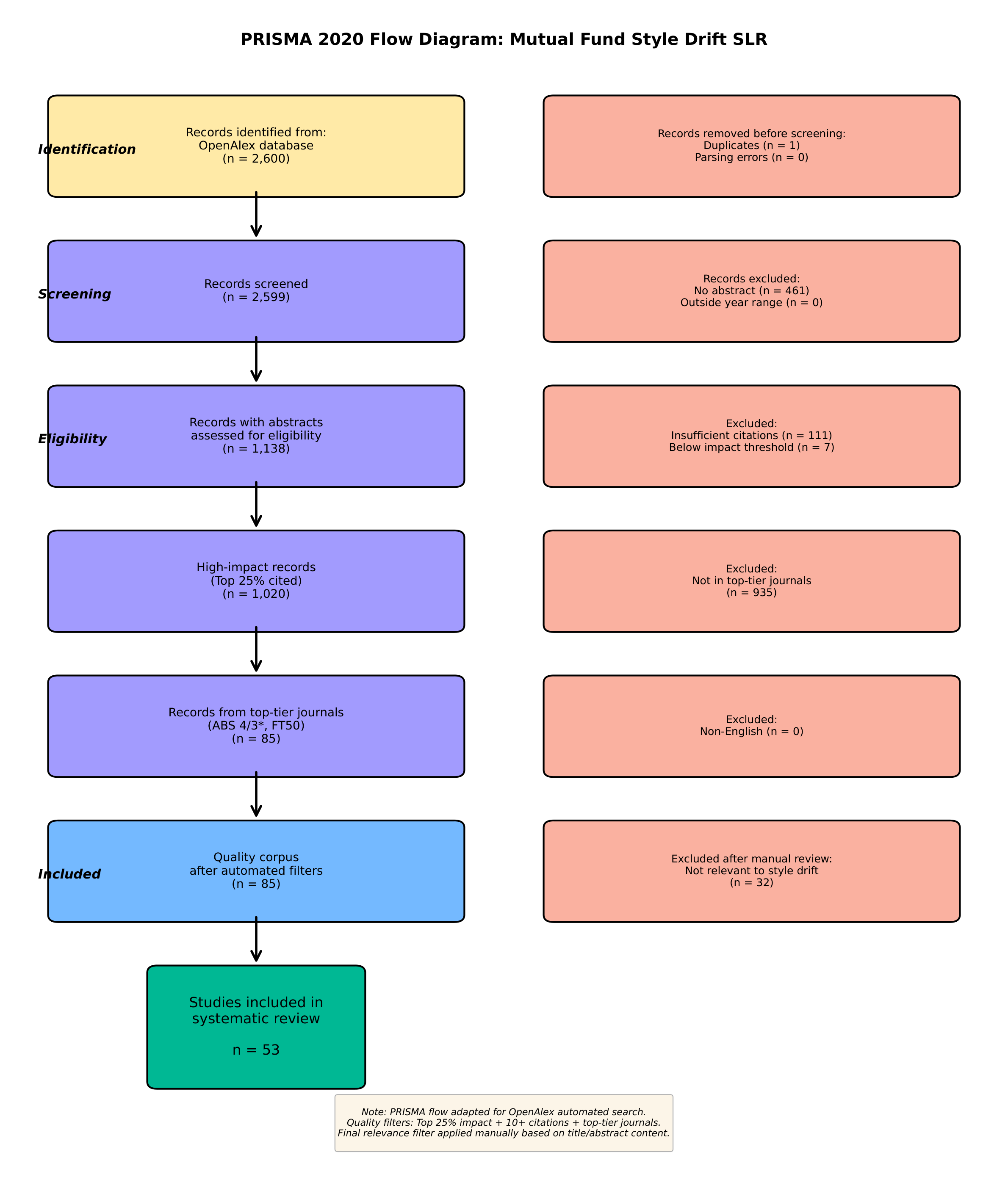
1.7 Quality Assessment
Rather than applying a standardized quality checklist (e.g., Newcastle-Ottawa Scale), we employed a pragmatic quality filter based on citation impact and journal tier. This approach is justified because: (1) the corpus spans three decades, making cross-temporal quality comparison via checklists problematic; (2) citation counts provide a market-based quality signal that aggregates expert assessments; and (3) journal tier serves as a pre-publication quality filter.
The resulting corpus has the following quality characteristics:
- Mean citations: 92.7 per paper
- Median citations: 38 per paper
- High-impact papers: 9 papers with 200+ citations, including seminal works by William F. Sharpe (1992), Martijn Cremers & Antti Petajisto (2009), and Stephen J. Brown & William N. Goetzmann (1997)
1.8 Data Extraction
For each included paper, we extracted: (1) bibliometric data (authors, year, journal, citations, DOI); (2) methodological classification (return-based vs. holdings-based, sample period and size); (3) key findings on drift measurement, causes, or consequences; and (4) thematic classification across six categories (see Section ). Data extraction was performed by a single researcher with independent verification of a 20\
Final corpus: 71 papers with 6,580 total citations (mean: 92.7, median: 38), spanning 1993–2025 across 30 unique journals. All DOIs were validated against CrossRef, with 100\