Unsupervised Learning
Unsupervised Learning
Discovering patterns in data without predefined labels.
Learning Outcomes
By completing this topic, you will:
- Explain when unsupervised learning is appropriate
- Compare clustering, dimensionality reduction, and association rules
- Evaluate cluster quality without ground truth
- Apply PCA for visualization
Visual Guides
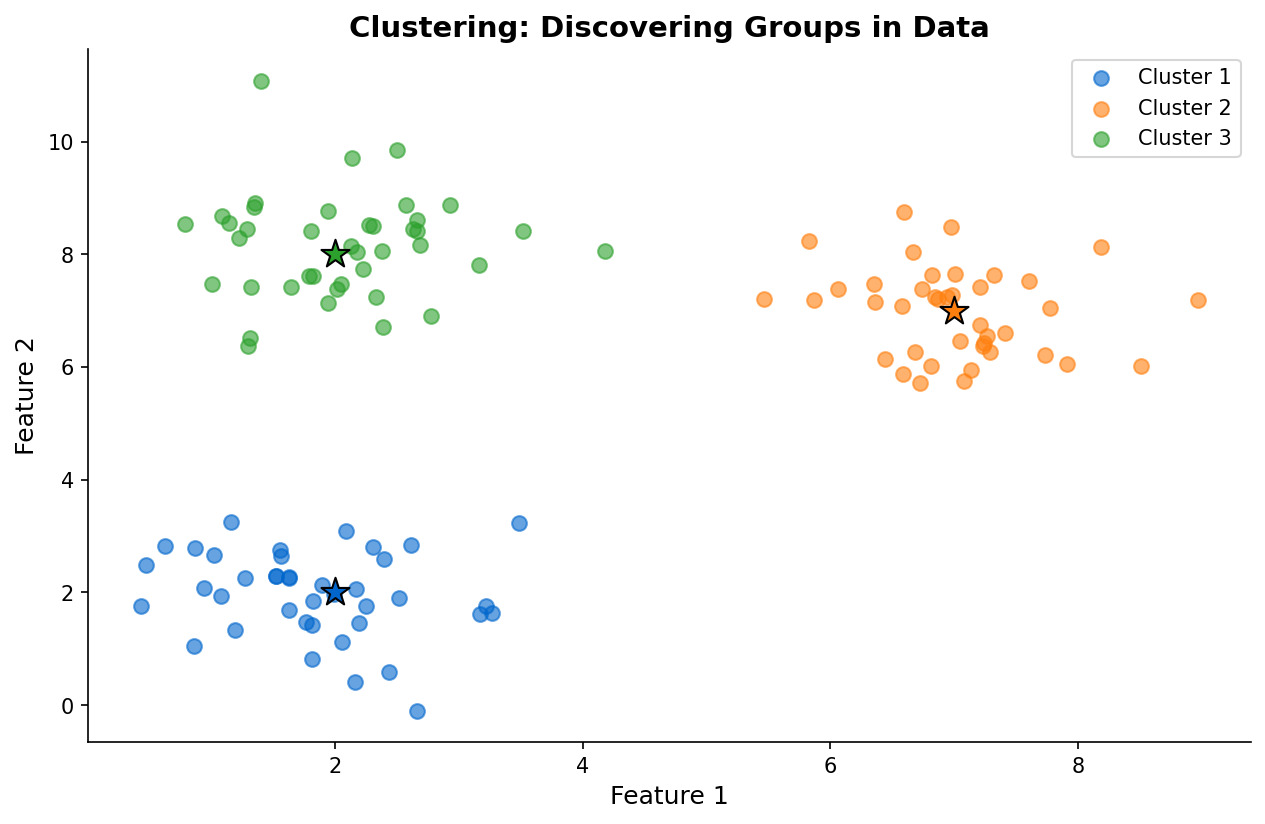
Clustering Example
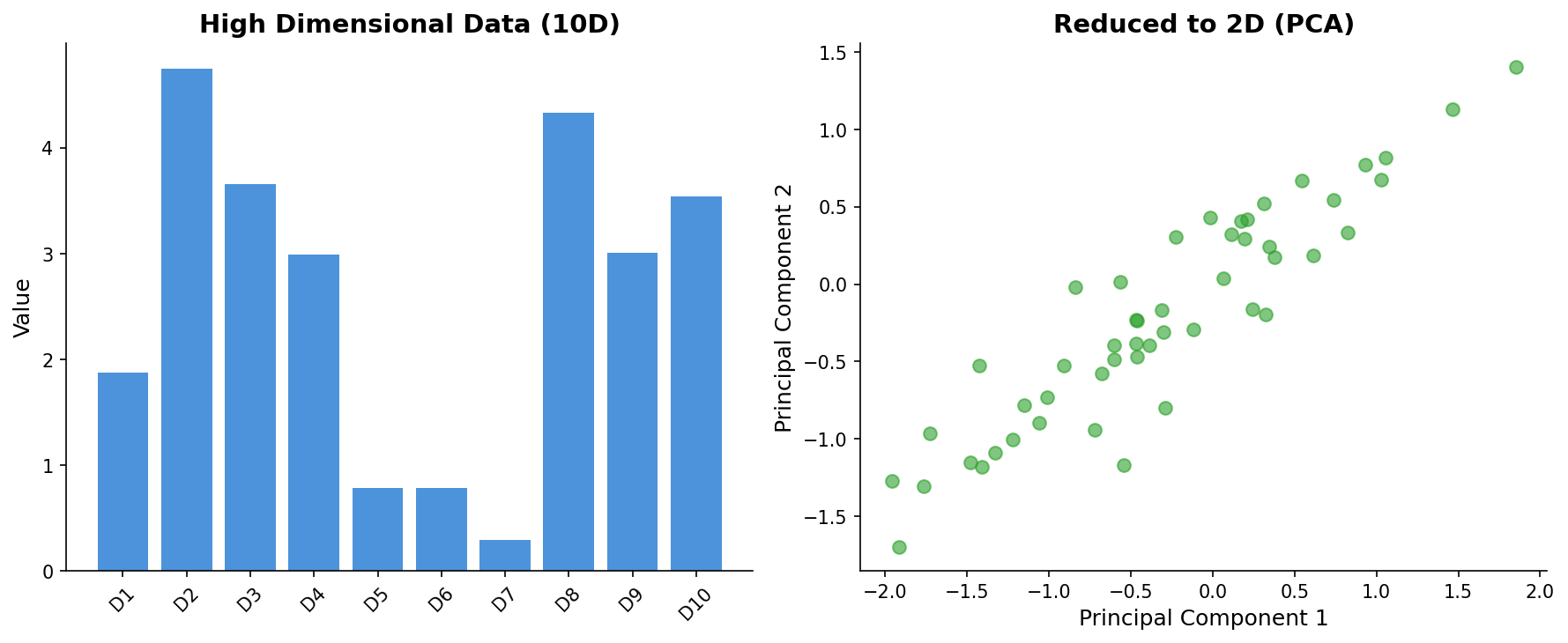
Dimensionality Reduction
Supervised vs Unsupervised
Prerequisites
- ML Foundations concepts
- Basic understanding of distance metrics
- Familiarity with data distributions
Key Concepts
Clustering
Group similar data points together:
- K-means for spherical clusters
- DBSCAN for arbitrary shapes
- Hierarchical for nested structures
Dimensionality Reduction
Compress high-dimensional data:
- PCA preserves variance
- t-SNE for visualization
- UMAP for structure preservation
Association Rules
Find relationships between items:
- Market basket analysis
- Support, confidence, lift metrics
When to Use
Unsupervised learning is ideal when:
- You lack labeled data
- You want to discover natural groupings
- You need to reduce feature dimensionality
- You want to find hidden patterns
Common Pitfalls
- Choosing K arbitrarily in K-means
- Ignoring the curse of dimensionality
- Over-interpreting cluster meanings
- Using wrong distance metric for data type
(c) Joerg Osterrieder 2025