NLP & Sentiment Analysis
NLP & Sentiment Analysis
Extracting meaning and emotion from text data.
Learning Outcomes
By completing this topic, you will:
- Preprocess text data (tokenization, normalization)
- Build sentiment classifiers
- Use pre-trained embeddings and transformers
- Evaluate NLP model performance
Visual Guides
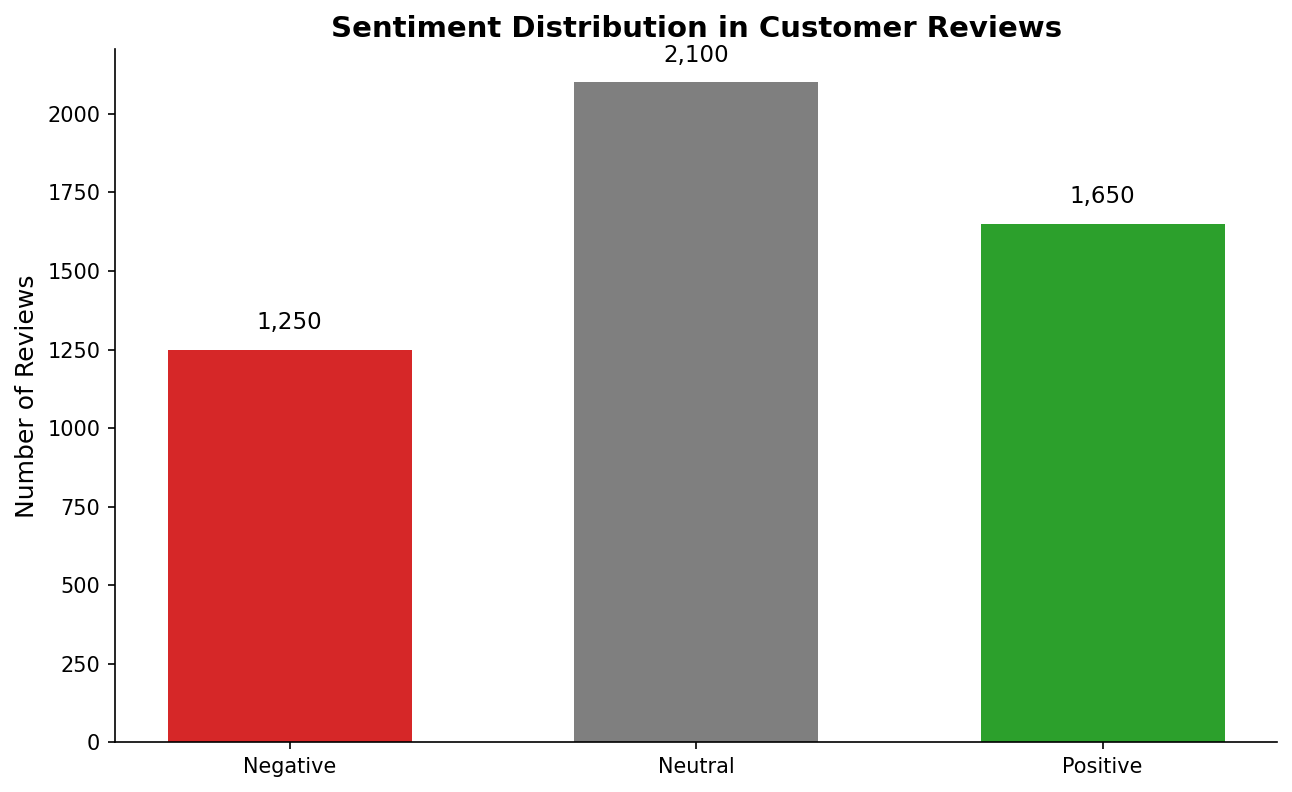
Sentiment Distribution
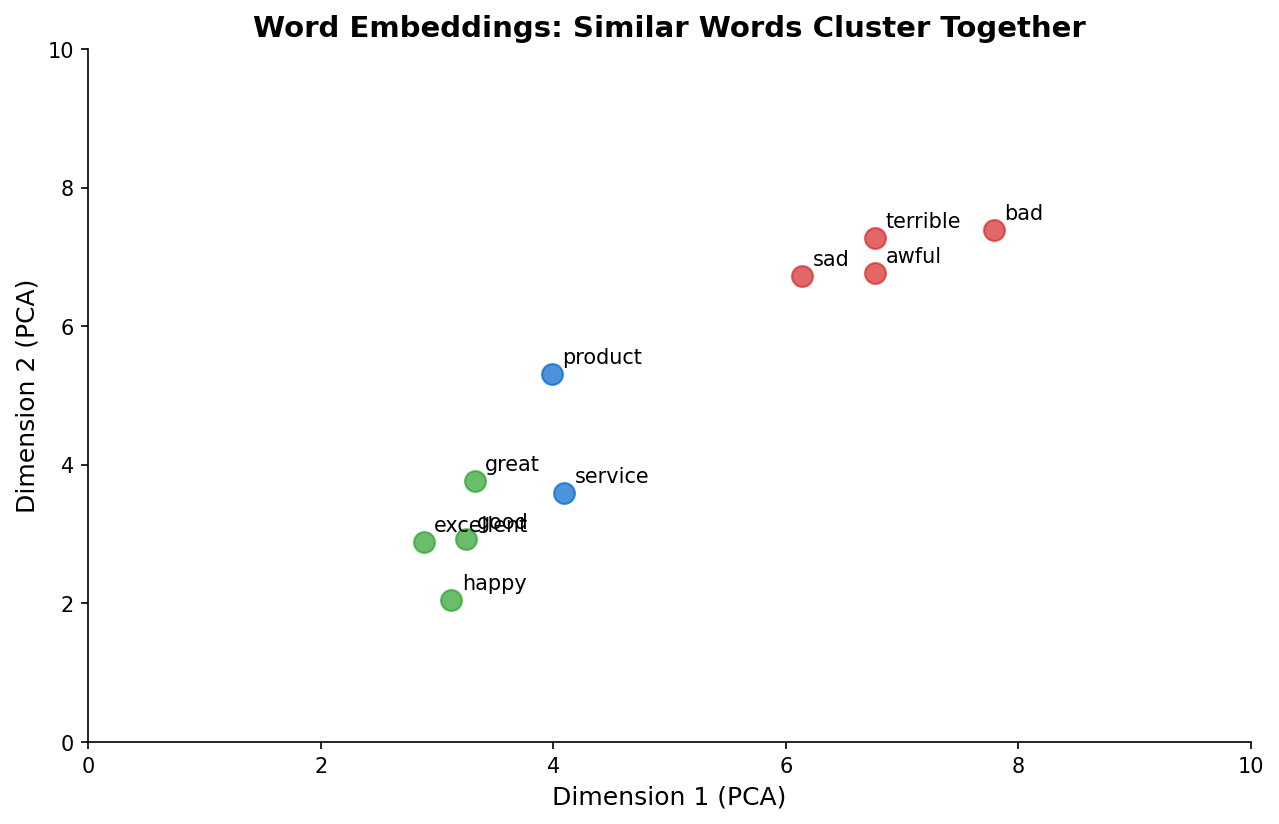
Word Embeddings
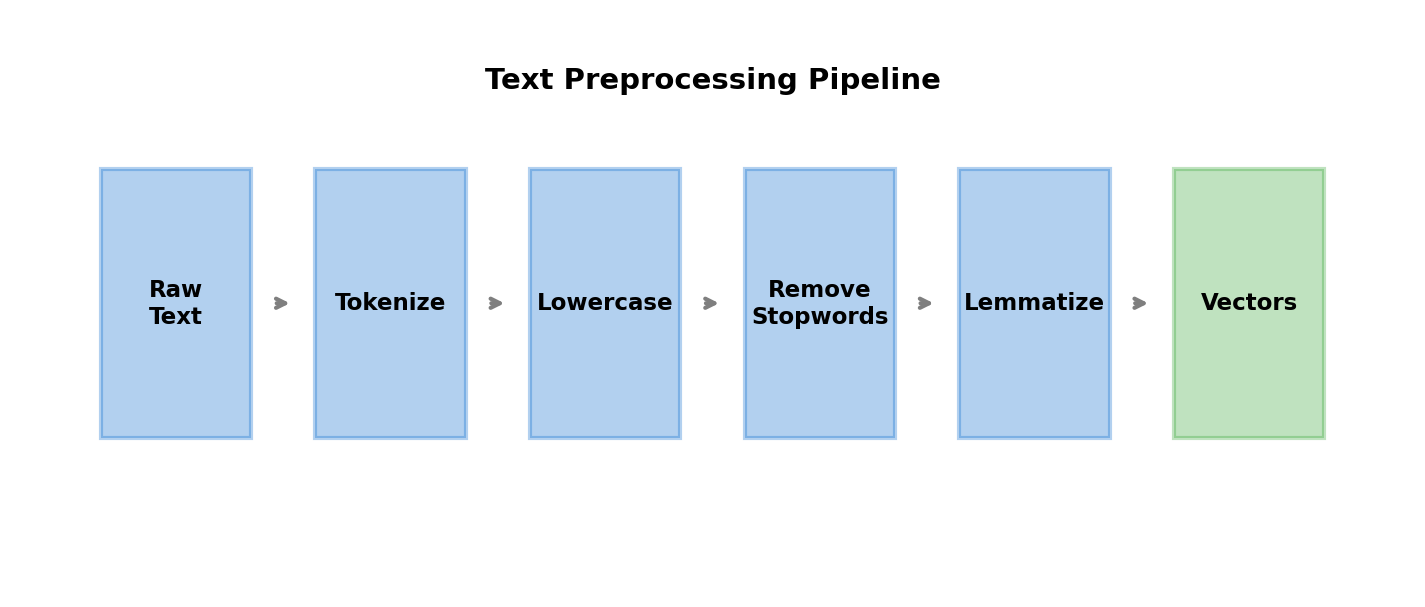
Text Preprocessing
Prerequisites
- Supervised Learning concepts
- Basic text processing concepts
- Understanding of classification metrics
Key Concepts
Text Preprocessing
- Tokenization: Split text into words/subwords
- Normalization: Lowercase, remove punctuation
- Stop word removal: Filter common words
- Stemming/Lemmatization: Reduce to root form
Sentiment Analysis Approaches
- Rule-based: Lexicons with sentiment scores
- Machine Learning: Train on labeled examples
- Deep Learning: Transformers (BERT, RoBERTa)
Word Embeddings
Dense vector representations:
- Word2Vec, GloVe (static embeddings)
- BERT (contextual embeddings)
When to Use
Sentiment analysis is valuable for:
- Customer feedback analysis
- Social media monitoring
- Brand perception tracking
- Product review summarization
Common Pitfalls
- Ignoring domain-specific vocabulary
- Not handling negation (“not good”)
- Overlooking sarcasm and irony
- Using general models on specialized text
- Ignoring class imbalance in training data
(c) Joerg Osterrieder 2025