Clustering
Clustering
Discovering natural groupings in data without predefined labels.
Learning Outcomes
By completing this topic, you will:
- Apply K-means, DBSCAN, and hierarchical clustering
- Choose the optimal number of clusters
- Interpret and validate cluster results
- Create customer personas from segments
Visual Guides
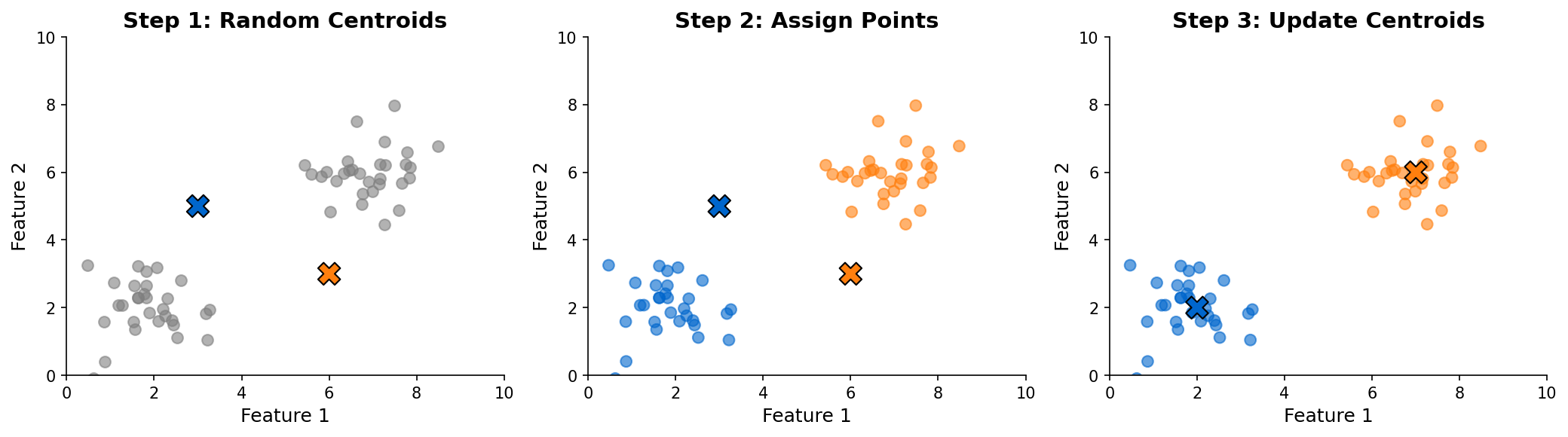
K-Means Algorithm
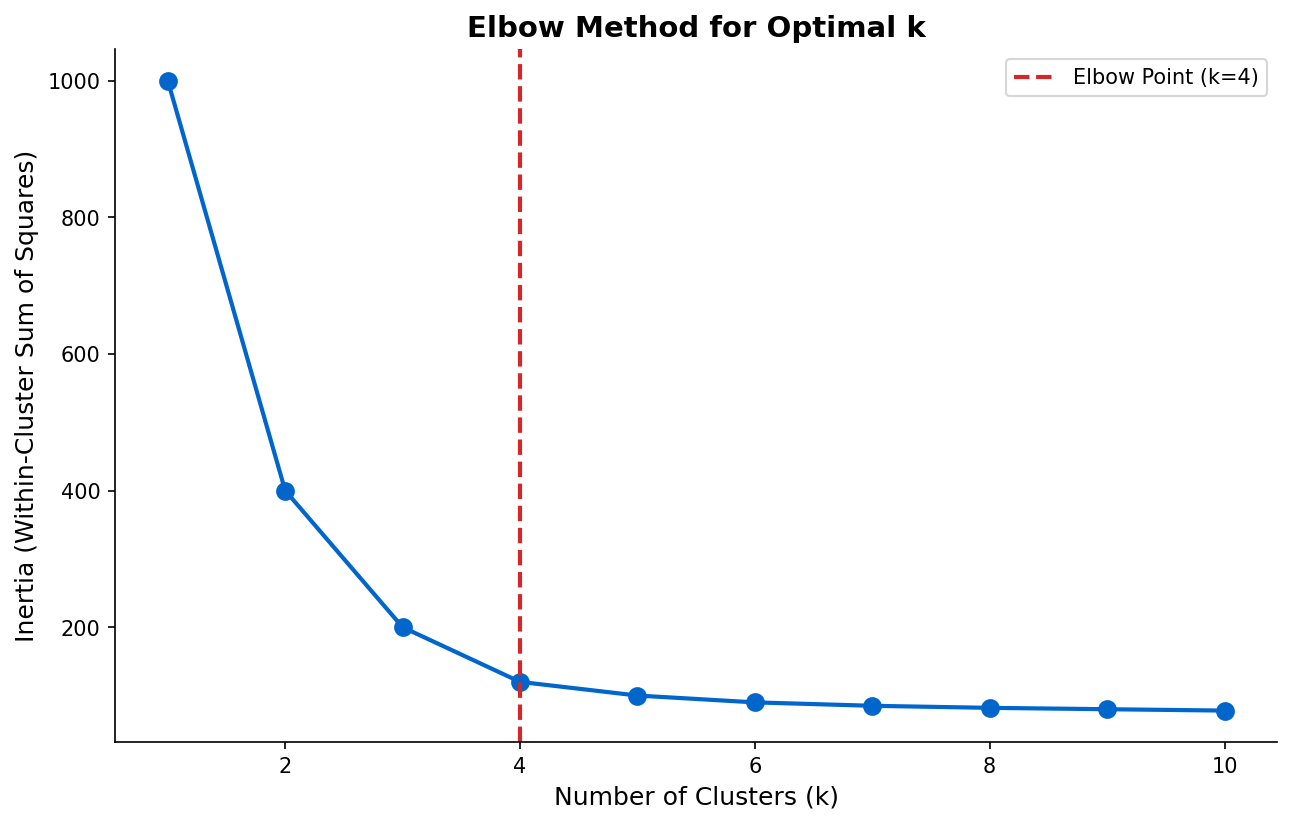
Elbow Method
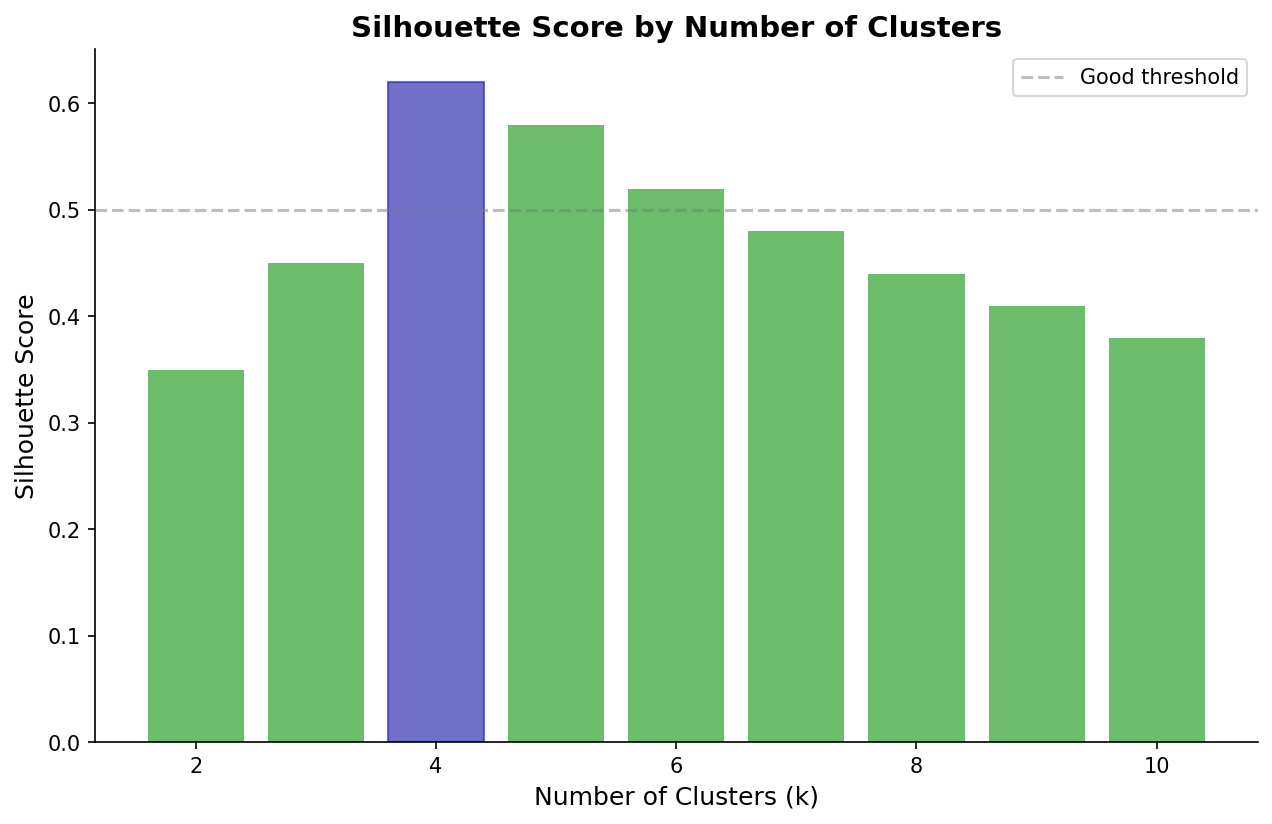
Silhouette Scores
Prerequisites
- Unsupervised Learning concepts
- Distance metrics (Euclidean, Manhattan)
- Feature scaling techniques
Key Concepts
K-Means Clustering
Partition data into K spherical clusters:
- Initialize K centroids
- Assign points to nearest centroid
- Update centroids as cluster means
- Repeat until convergence
Choosing K: Elbow method, silhouette score
DBSCAN
Density-based clustering for arbitrary shapes:
- Epsilon: Neighborhood radius
- MinPts: Minimum points to form a cluster
- Automatically detects noise points
Hierarchical Clustering
Build nested cluster hierarchy:
- Agglomerative (bottom-up)
- Divisive (top-down)
- Dendrograms for visualization
When to Use
| Algorithm | Best For |
|---|---|
| K-means | Spherical clusters, known K |
| DBSCAN | Arbitrary shapes, noise detection |
| Hierarchical | Exploring cluster structure |
Common Pitfalls
- Not scaling features before clustering
- Choosing K based on convenience, not data
- Ignoring cluster interpretability
- Using K-means on non-spherical data
- Forgetting to validate cluster stability
(c) Joerg Osterrieder 2025